在 Elasticsearch 或者 Easysearch 这样的搜索引擎中,写入流程是理解性能调优和搜索可见性最核心的部分之一。许多同学刚接触 ES 时,最常见的疑惑就是:“为什么我刚插入的数据查不到?”、“refresh 和 flush 有什么区别?”、“refresh_interval 设置成多少合适?”
这篇文章我们就专门讲清楚 refresh(刷新) 这一环节。它是 ES 写入流程的关键节点,既影响了数据什么时候能被搜索到,也影响了整个系统的写入性能和稳定性。
1. 什么是刷新时间
1.1 refresh 的定义
刷新 (refresh) = 把 内存 buffer 里的数据写到新的 segment 文件(先进入 OS cache),然后让它们对搜索可见。
刷新时间 (refresh interval) = ES 自动触发 refresh 的周期。
换句话说,refresh 的目标不是“数据持久化”,而是“数据可见”。也就是说,数据写进来之后,先保存在内存 buffer 里,这时候你去搜索是查不到的;一旦发生了 refresh,这些数据就会生成一个新的 Lucene segment,被索引打开,立即可搜索。
1.2 为什么需要 refresh?
Lucene 是一个基于 segment 的倒排索引系统。segment 文件是 只读的,所以每次有新文档进来,都要生成新的 segment。refresh 就是触发这个生成过程的机制。 如果没有 refresh,你写入的数据永远停留在 buffer 里,不会变成 segment,自然也就查不到。
2. 默认值与查询验证
默认情况下,ES 的 refresh_interval 是 1s。也就是说,ES 每秒会自动刷新一次,所以新写入的数据通常 1 秒内就能查到。
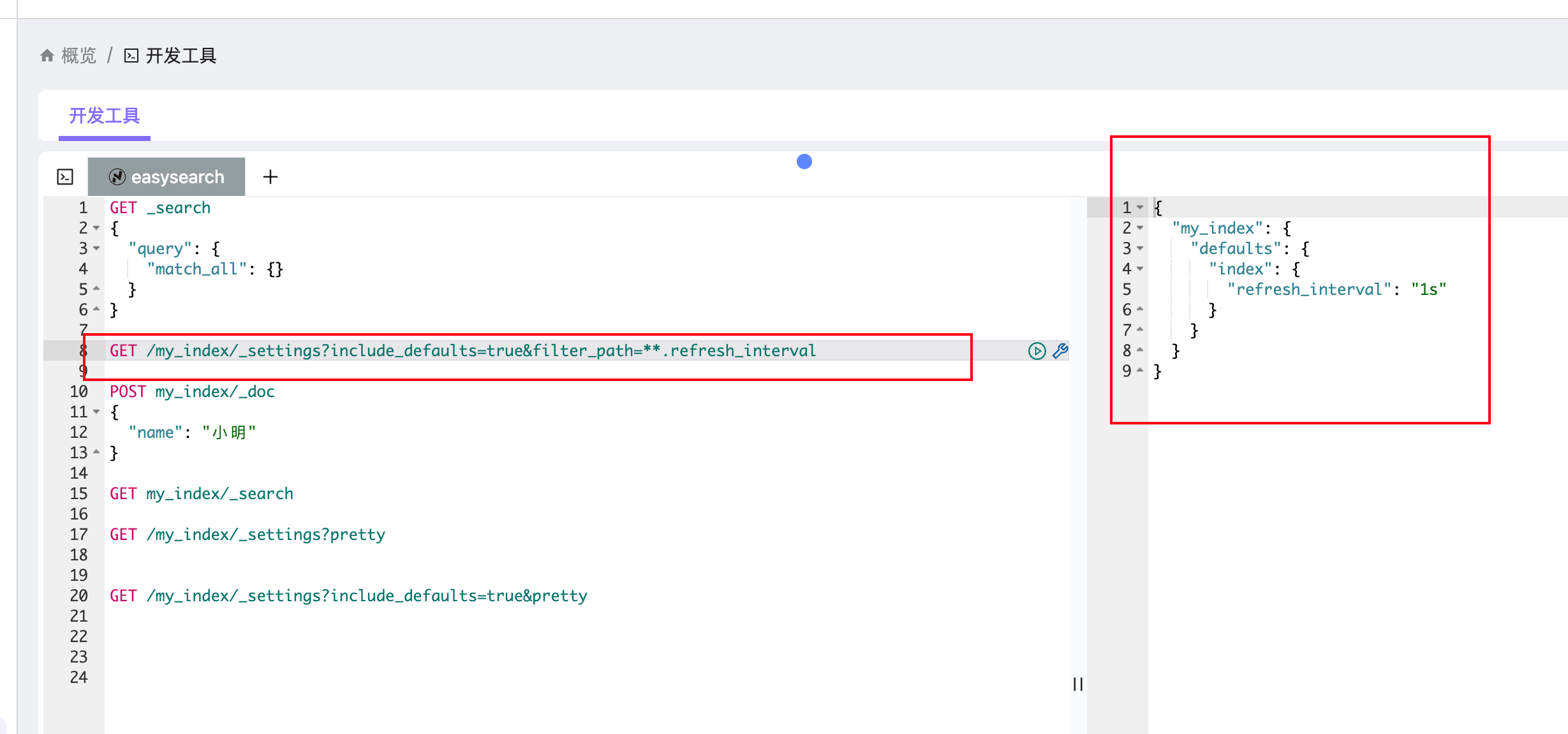
我们可以通过 _settings API 来查看:
# 查看某个索引的 refresh_interval
GET /my_index/_settings?include_defaults=true&filter_path=**.refresh_interval返回结果示例:
{
"my_index": {
"settings": {
"index": {
"refresh_interval": "1s"
}
}
}
}这说明 my_index 索引的刷新间隔是 1 秒。
如果你刚写入一条文档,立刻查询可能查不到,但只要等 1 秒钟,它就会出现在搜索结果里。这个“近实时(Near Real Time, NRT)”特性,就是 ES 的核心设计。
3. 修改刷新时间
在不同场景下,1 秒钟的 refresh_interval 并不是最优的。有时候我们希望更快可见,有时候则希望尽量少刷新,以提高写入性能。ES 允许你动态修改刷新间隔。
# 设置为 30s(减少频繁刷新,写入性能更高)
PUT /my_index/_settings
{
"index": {
"refresh_interval": "30s"
}
}
# 禁用自动刷新(批量写入时常用)
PUT /my_index/_settings
{
"index": {
"refresh_interval": "-1"
}
}- 设置为
30s:表示 30 秒刷新一次。适合日志类场景,写多查少,降低频繁小 segment 的生成。 - 设置为
-1:表示完全禁用自动 refresh,只能通过手动_refresh让数据可见。这个模式常见于 大批量数据导入。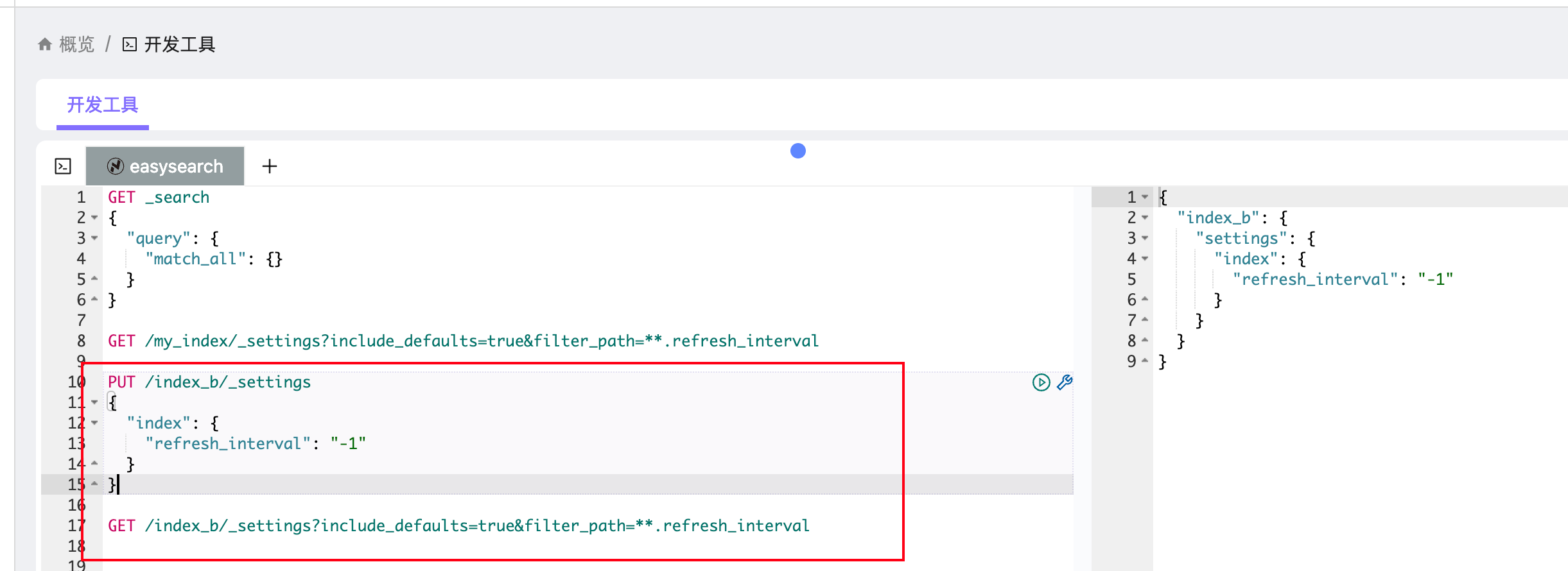
4. 取值含义与场景适配
"1s":默认值,平衡写入和查询,适合绝大多数通用场景。"30s"或更大:适合日志/监控场景,写多查少,减少小 segment 生成,提高写入吞吐。"-1":禁用自动刷新,通常用于大规模初始化导入数据。导入完成后,手动 refresh,再改回默认值。
5. 刷新时间对性能的影响
理解 refresh_interval 的性能影响非常重要。
时间越短(比如 500ms、1s)
- 优点:几乎实时可见,写入后很快就能查询到。
- 缺点:会生成大量小 segment,触发频繁的合并,降低整体写入吞吐。
时间越长(比如 30s、60s)
- 优点:减少 segment 数量,提升写入效率。
- 缺点:数据可见延迟更高。
禁用自动 refresh
- 优点:写入性能最佳,可以最大化导入速度。
- 缺点:完全不可查,必须手动 refresh 才能看到数据。
6. 实战建议
- 普通搜索型索引(电商商品、用户数据):用默认
1s。 - 日志/监控索引(写多查少):调大到
30s或60s,甚至更长。 - 大批量导入(初始化数据):设置
-1,导入后手动 refresh,再恢复1s。
这种调优思路能够兼顾写入性能和搜索体验。
| refresh_interval | 数据可见性 | 写入性能 | 典型场景 |
|---|---|---|---|
1s (默认) | ~1s 可查 | 中等 | 电商搜索、通用场景 |
30s | ~30s 可查 | 较高 | 日志、监控 |
-1 | 手动可查 | 最高 | 大规模数据导入 |
7. refresh 参数取值详解
在写入 API 里,还可以通过 refresh 参数控制是否立刻刷新:
refresh=false(默认)- 不会自动 refresh,性能最好。
- 新写的数据需要等下一个 refresh 周期才能查到。
refresh=true- 执行完后强制 refresh。
- 数据立即可见,但每次都会触发 refresh,性能代价较大。
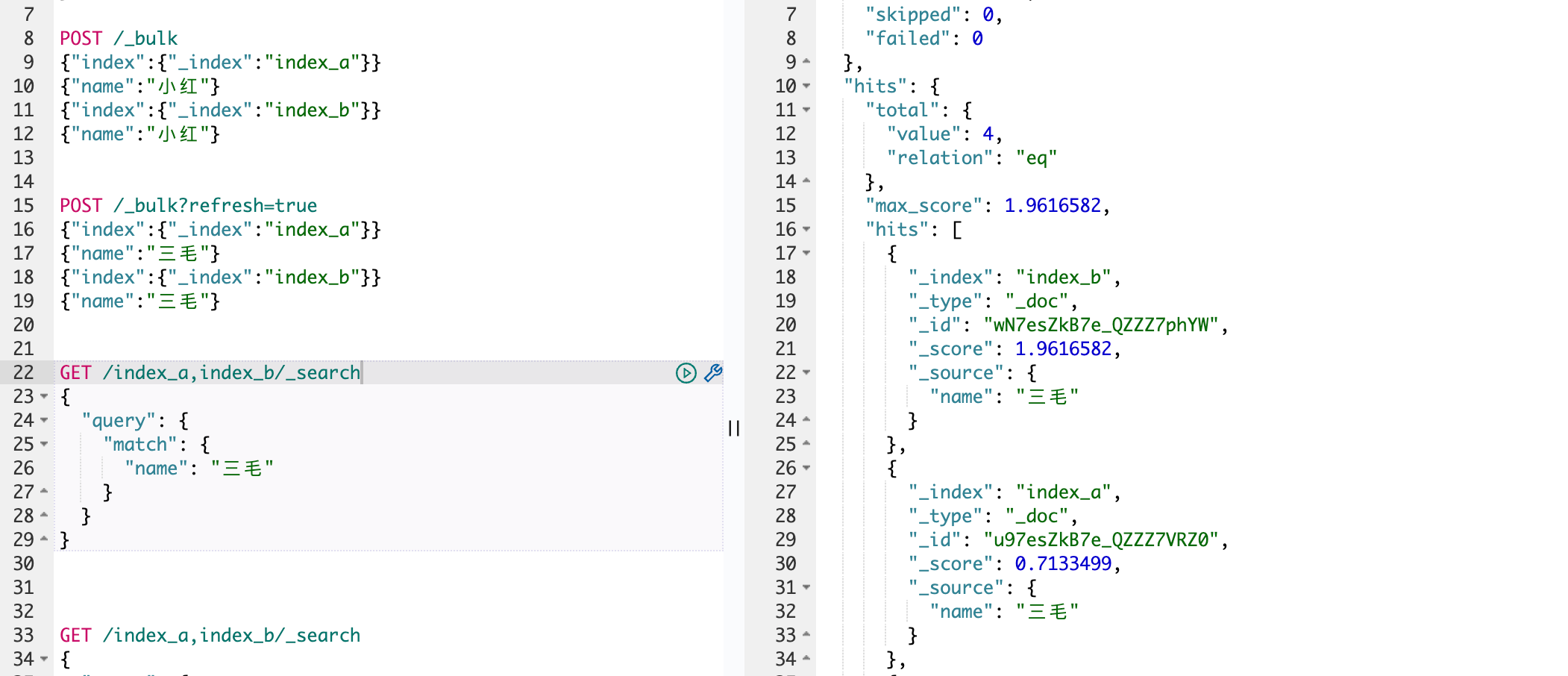
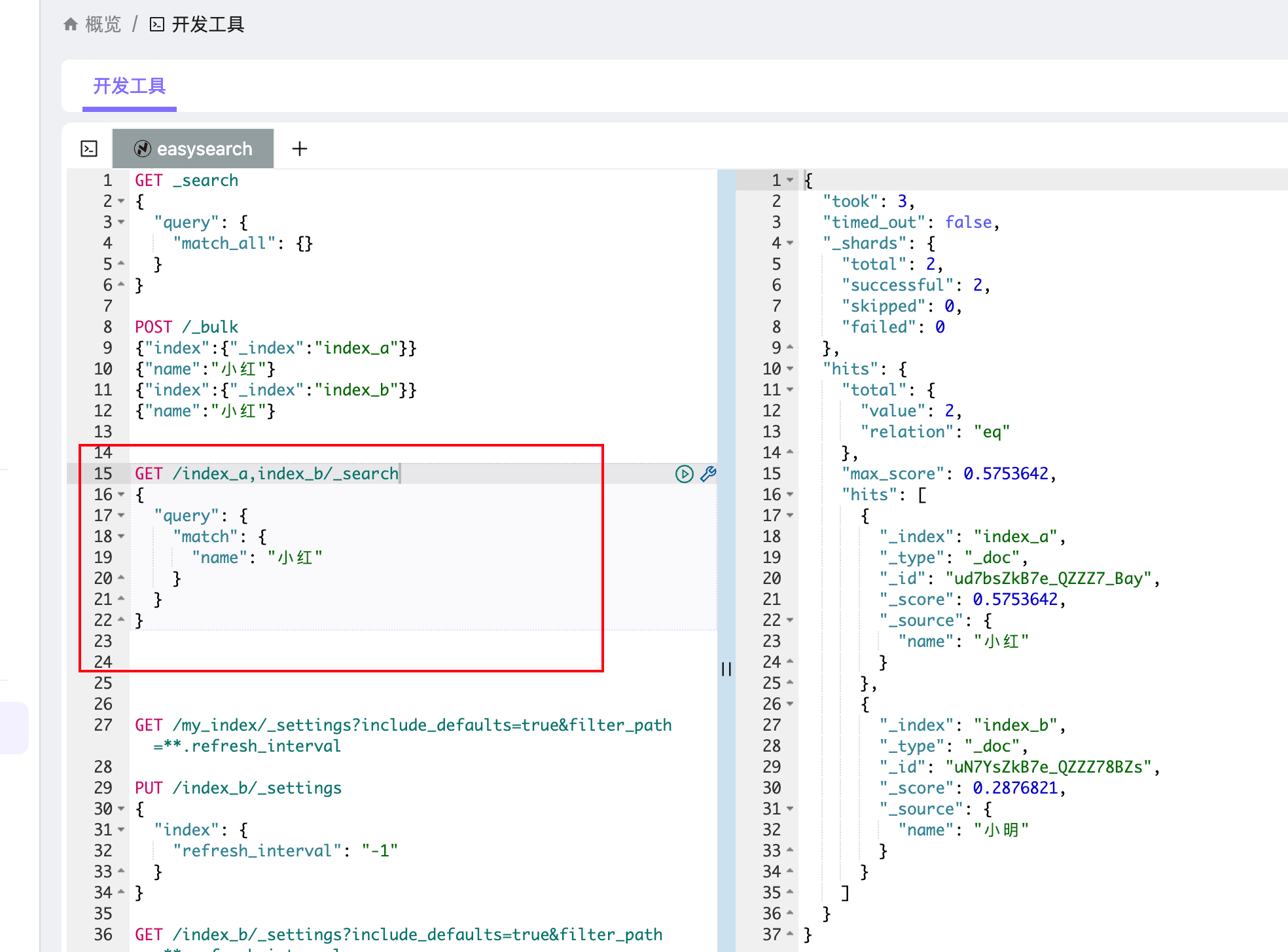
我们能够看到,即使 index_b 前面设置了"refresh_interval": "-1",再手动 refresh 之后也能够查找到了。
refresh=wait_for- 不强制立即 refresh,而是等待下一个 refresh 周期完成后再返回。
- 适合既想要数据可见,又不想过多消耗性能的场景。
- 注意:如果索引设置了
"refresh_interval": "-1",那么wait_for会一直卡住不返回,这时候最好手动 refresh。
8. 手动刷新索引
在 Easysearch 里,手动刷新索引 就是调用 _refresh API。 这个操作会立刻把 内存 buffer 里的数据写到新的 segment(进入 OS cache),并让它们对搜索可见。

# 刷新单个索引
POST /my_index/_refresh
# 刷新多个索引
POST /index_a,index_b/_refresh
# 刷新整个集群
POST /_refresh使用场景:
- 测试时:写入数据 → 立刻刷新 → 马上查。
- 批量导入时:禁用自动 refresh,导入完成后一次性手动 refresh。
⚠️ 注意:频繁手动 refresh 会导致大量小 segment,性能很差。生产环境中要谨慎使用。
9. 写入生命周期时间轴
为了更直观理解,我们看下 ES 写入生命周期:
时间轴 →
[写入] [refresh] [flush]
│ │ │
▼ ▼ ▼
文档写入 → Indexing Buffer → Segment(OS cache) → fsync磁盘
+ Translog(日志)9.1 文档写入 (t=0)
- 文档进入 内存 buffer
- 同时写入 translog
- 此时数据不可查询。
9.2 refresh (t = refresh_interval)
- buffer 转换为新的 segment 文件
- segment 进入 OS cache
- Lucene 打开 segment,数据可查询,但未必落盘。
9.3 flush
- 强制 fsync,把 OS cache 写到磁盘
- 清空 translog
- 此时数据既可查询,也保证持久化。
最佳实践流程:批量导入优化
- 新建索引 → 设置
refresh_interval=-1。 - 使用
_bulk批量导入数据。 - 导入完成后,手动执行
POST /my_index/_refresh。 - 恢复
refresh_interval=1s(或业务需要的值)。
这样能显著提升导入性能,同时保证导入完成后数据立即可见。
📌 总结
- refresh 决定了写入数据多久能被查询到。
- 它与 flush 不同:flush 是保证持久化,refresh 是保证可见性。
- 默认
1s,意味着 ES 是一个“近实时”系统。 - 在写多查少的场景,调大 refresh_interval 能显著提升性能。
- 在大规模导入时,禁用 refresh,然后手动 refresh,是常见的优化手法。
理解 refresh,不仅能帮助你解决“为什么数据查不到”的问题,还能让你在性能和实时性之间做出合理的权衡。

